


行業新聞
打通機器視覺與自然語言處理,Facebook正讓機器“看圖說話”
日期:2017-12-22
來源:三姆森科技
“視覺對話”(Visual Dialogue)是個最近新興的研究方向。它集機器視覺、自然語言處理、以及對話系統這三個十分熱門的研究方向為一體,主要目標就是教會機器如何用自然語言與人類交流視覺數據。
現有的對話系統能力范圍極廣:在這個范圍的一頭是為特定目標設計的任務驅動的聊天機器人,比如可以幫你訂飛機票聊天機器人,而在另一頭則是可以和你侃大山的“閑聊機器人”。在這個范圍里,視覺對話處于這兩個極端中間:它是自由的對話,但是對話的內容卻會受到一個具體的圖像的限制。


對視覺內容進行明確的推理
語言與視覺數據最重要的關聯之一就是用自然語言提問,比如:“圖片中的動物是什么?”,或者“沙灘上坐著多少人?”雖然每個問題都要求解決不同的問題,但是目前絕大多數最先進的系統都會使用整體方法,比如同樣的計算圖或者網絡來計算出答案。但是,這種模型的解釋性有限,并且對更復雜的推理任務,比如下圖中所展示的“有多少物體的體積與那個球一樣?”來說效率不高。
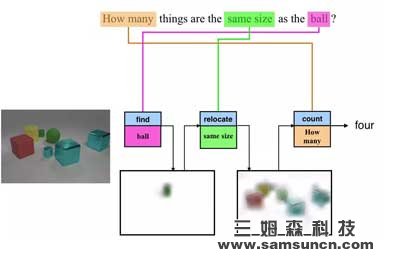
在上圖中的例子里,一個模塊會“尋找”圖中的球,另外一個模塊則會“尋找”同樣體積的物體,而最后一個模塊則會數“有多少”這樣的物體。最重要的是,這些模塊可以重復的用于不同的圖片和問題,比如“找球”模塊也可以用來回答“圖中的球比立方體多嗎?”這個問題。從圖中,我們還可以看到中間以“注意圖”(Attention Map)的方式告訴我們模型正在看哪個部位的那些步驟是一種可被理解的輸出。
雖然原先的成功所依賴的是一個不可微的自然語言處理器,2017 年的 ICCV(國際計算機視覺大會)上有兩篇論文展示了如何從端到端的訓練這種系統。這兩篇論文的作者發現,這種方式對于回答 CLEVR 數據集中的困難成分問題來說至關重要。(CLEVR 數據集是在 CVPR 2016 所公布的一款用于測試成分語言和基本視覺推理的數據集,后由 Facebook 人工智能研究室(FAIR)和斯坦福大學聯手公開)。
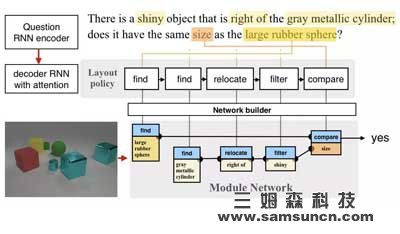 圖 |在《Learning to Reason: End-to-End Module Networks for Visual Question Answering》一文中,作者們首先在問題上做出了一個含有編碼器和解碼器的遞歸神經網絡(RNN)的政策/程序。這個程序再搭建了一個模塊網絡,并在圖片上運行這個網絡來回答問題。
圖 |在《Learning to Reason: End-to-End Module Networks for Visual Question Answering》一文中,作者們首先在問題上做出了一個含有編碼器和解碼器的遞歸神經網絡(RNN)的政策/程序。這個程序再搭建了一個模塊網絡,并在圖片上運行這個網絡來回答問題。
不過,這兩篇論文提出了兩種不同的構架。在第一篇,由 Facebook 人工智能研究院和斯坦福大學聯手發表的論文(Inferring and Executing Programs for Visual Reasoning)中,研究人員們在不同的模塊中使用了不同的參數,但又使用了同樣的網絡結構。在第二篇,由 Facebook 人工智能研究院和加州大學伯克利分校,以及波士頓大學聯手發表的論文(Learning to Reason: End-to-End Module Networks for Visual Question Answering)中,作者們在不同的模塊中采取了不同的計算方式,但是又通過嵌入問題所用的語言分享了參數。
雖然這兩款模型的構架不一樣,但是它們卻得出了一個同樣的結論:我們在監督程序預測時需要使用正確參考標準(Ground Truth)程序來確保結果,不過我們僅需少量的訓練數據。此外,第一篇論文(Inferring and Executing Programs )還顯示,使用加強學習來讓網絡學會最優的端到端還比正確參考標準程序提高了很多,并且可以針對新問題和答案進行精準的調整。
而最近又出現了兩款網絡構架:RelationNet 和 FiLM。在訓練時不使用任何正確參考標準程序的情況下,使用這兩個構架的整體網絡不但保持了性能,甚至還實現了提高。當然,這也意味著它們失去了原有的明確和可理解的推理結構。
此外,第一篇論文(Inferring and Executing Programs)使用的從人群中收集到的問題,而不是 CLEVR 數據集里那些生成的問題。在這方面,沒有任何模型表現出了良好的普遍性。相似的是,在使用視覺問答(Visual Question Answering,VQA)數據集中的真實圖片和問題進行測試時,第二篇論文(Learning to Reason)只實現了有限的性能提高,很有可能因為 VQA 數據集中的問題不需要像 CLEVR 數據集里的那么困難的推理。總體來說,我們很高興可以在未來探索新的主意,搭建真正具有成分性和解釋性的模型,來對應現實世界中新的設置和程序所創造的挑戰。
擬人的視覺對話
Dhruv Batra,Devi Parikh,以及他們在佐治亞理工學院和卡耐基梅隆大學的學生們針對嵌入在圖片中的自然語言對話進行了研究,并且開發出來一款全新的 2 人對話數據收集協議,來生成一個大規模的視覺對話數據集(VisDial)。這個數據集中針對 12 萬張圖片的每段對話都有 10 對問答,共有 120 萬對對話問答。
為了解決這一問題,佐治亞理工學院,卡耐基梅隆大學,以及 Facebook 人工智能研究院的研究人員們推出了全世界首個由目標驅動(深度加強學習),來幫助訓練視覺問答以及視覺對話代理的論文:“Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning”。
他們開發出一款合作“圖片猜測”游戲 GuessWhich,要求一個“提問者”Q-BOT 和一個“回答者”A-BOT 用自然語言進行對話。在游戲開始之前,A-BOT 會被提供一張 Q-BOT 不知道的圖片,而 A-BOT 和 Q-BOT 都會被提供同樣的對圖片的自然語言描述。在接下來的每輪中,Q-BOT 都會生成一個問題,A-BOT 對這個問題作出回答,然后兩者更新它們的狀態。在 10 輪之后,Q-BOT 必須猜測這張圖片,即在多張圖片中選出這張圖片。
我們發現,這些加強學習訓練出來的機器人的性能遠超傳統監督學習產生的機器人。最有意思的是,雖然監督學習的 Q-BOT 會嘗試模仿人類問問題,加強學習的 Q-BOT 卻會改變策略,提出 A-BOT 更擅長回答的問題,最終產生得到最多信息,最有益于團隊的對話。
由目標驅動的訓練的一個替代品就是使用可以區分人類和代替生成回答的對抗性損失或者知覺喪失。這個主意已經由 Facebook 人工智能研究院以及佐治亞理工學院的研究人員在研究了,并且會在 NIPS 2017(神經信息處理系統大會)公布他們的成果:“Best of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Mode”。
此外,這篇由德國的馬普信息學研究所,加州大學伯克利分校,以及 Facebook 人工智能研究院的研究人員所發表的論文:“Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training”也是針對這個話題的。這篇論文表示,在同一時間為一張圖片生成多個描述,要比一次生成一個更能讓模型學會如何生成更多樣化,更擬人的圖片描述。
我們需要開放的跨領域合作
作為人類,我們大腦功能種很重要的一部分都是通過視覺處理,而自然語言則是我們交流的方式。創造可以將視覺和語言連接在一起的人工智能代理是一個即興奮也困難的任務。我們在此文中討論了兩個研究方向:明確的視覺推理和擬人的視覺對話。雖然我們在進步,但是我們面前還有許多挑戰。為了保證向前的腳步不停,堅持在 Facebook 人工智能研究院,學術界,以及整個人工智能生態圈之間機型長期開放的基礎性跨領域研究合作是至關重要的。
現有的對話系統能力范圍極廣:在這個范圍的一頭是為特定目標設計的任務驅動的聊天機器人,比如可以幫你訂飛機票聊天機器人,而在另一頭則是可以和你侃大山的“閑聊機器人”。在這個范圍里,視覺對話處于這兩個極端中間:它是自由的對話,但是對話的內容卻會受到一個具體的圖像的限制。
圖 | 未來可能的應用 1:一個智能代理通過視覺能力和自然語言推理來幫助(組織)一個人停在消防栓前面
雖然視覺對話的研究還處于初期,但是這項技術已經有著眾多的應用場景了。比如通過一系列問答來幫助弱視或盲人理解網上的圖片以及拍攝周圍的照片,或者幫助醫療人員更好的理解醫療成像。它也可以用于虛擬現實(VR)或增強現實(AR)程序里,幫助用戶與虛擬伙伴用語言針對所見到的畫面進行交流。
圖:未來可能的應用 2:一個虛擬伙伴通過看到與用戶相同的圖片來進行交流
在達到這一點之前,我們需要攻克許多基礎性的難關。最近,Facebook 針對兩點進行了研究:一個是對視覺內容進行明確的推理,一個是擬人的視覺對話。對視覺內容進行明確的推理
語言與視覺數據最重要的關聯之一就是用自然語言提問,比如:“圖片中的動物是什么?”,或者“沙灘上坐著多少人?”雖然每個問題都要求解決不同的問題,但是目前絕大多數最先進的系統都會使用整體方法,比如同樣的計算圖或者網絡來計算出答案。但是,這種模型的解釋性有限,并且對更復雜的推理任務,比如下圖中所展示的“有多少物體的體積與那個球一樣?”來說效率不高。
圖 | 將問題模塊化可以實現可解釋以及成分推理
為了解決這一問題,加州大學伯克利分校的研究人員在 2016 年的 CVPR(IEEE 國際計算機視覺與模式識別會議)上提出了一種“神經模塊網絡(Neural Module Networks)”,可以將計算分解成明確的模塊。在上圖中的例子里,一個模塊會“尋找”圖中的球,另外一個模塊則會“尋找”同樣體積的物體,而最后一個模塊則會數“有多少”這樣的物體。最重要的是,這些模塊可以重復的用于不同的圖片和問題,比如“找球”模塊也可以用來回答“圖中的球比立方體多嗎?”這個問題。從圖中,我們還可以看到中間以“注意圖”(Attention Map)的方式告訴我們模型正在看哪個部位的那些步驟是一種可被理解的輸出。
雖然原先的成功所依賴的是一個不可微的自然語言處理器,2017 年的 ICCV(國際計算機視覺大會)上有兩篇論文展示了如何從端到端的訓練這種系統。這兩篇論文的作者發現,這種方式對于回答 CLEVR 數據集中的困難成分問題來說至關重要。(CLEVR 數據集是在 CVPR 2016 所公布的一款用于測試成分語言和基本視覺推理的數據集,后由 Facebook 人工智能研究室(FAIR)和斯坦福大學聯手公開)。
不過,這兩篇論文提出了兩種不同的構架。在第一篇,由 Facebook 人工智能研究院和斯坦福大學聯手發表的論文(Inferring and Executing Programs for Visual Reasoning)中,研究人員們在不同的模塊中使用了不同的參數,但又使用了同樣的網絡結構。在第二篇,由 Facebook 人工智能研究院和加州大學伯克利分校,以及波士頓大學聯手發表的論文(Learning to Reason: End-to-End Module Networks for Visual Question Answering)中,作者們在不同的模塊中采取了不同的計算方式,但是又通過嵌入問題所用的語言分享了參數。
雖然這兩款模型的構架不一樣,但是它們卻得出了一個同樣的結論:我們在監督程序預測時需要使用正確參考標準(Ground Truth)程序來確保結果,不過我們僅需少量的訓練數據。此外,第一篇論文(Inferring and Executing Programs )還顯示,使用加強學習來讓網絡學會最優的端到端還比正確參考標準程序提高了很多,并且可以針對新問題和答案進行精準的調整。
而最近又出現了兩款網絡構架:RelationNet 和 FiLM。在訓練時不使用任何正確參考標準程序的情況下,使用這兩個構架的整體網絡不但保持了性能,甚至還實現了提高。當然,這也意味著它們失去了原有的明確和可理解的推理結構。
此外,第一篇論文(Inferring and Executing Programs)使用的從人群中收集到的問題,而不是 CLEVR 數據集里那些生成的問題。在這方面,沒有任何模型表現出了良好的普遍性。相似的是,在使用視覺問答(Visual Question Answering,VQA)數據集中的真實圖片和問題進行測試時,第二篇論文(Learning to Reason)只實現了有限的性能提高,很有可能因為 VQA 數據集中的問題不需要像 CLEVR 數據集里的那么困難的推理。總體來說,我們很高興可以在未來探索新的主意,搭建真正具有成分性和解釋性的模型,來對應現實世界中新的設置和程序所創造的挑戰。
擬人的視覺對話
Dhruv Batra,Devi Parikh,以及他們在佐治亞理工學院和卡耐基梅隆大學的學生們針對嵌入在圖片中的自然語言對話進行了研究,并且開發出來一款全新的 2 人對話數據收集協議,來生成一個大規模的視覺對話數據集(VisDial)。這個數據集中針對 12 萬張圖片的每段對話都有 10 對問答,共有 120 萬對對話問答。
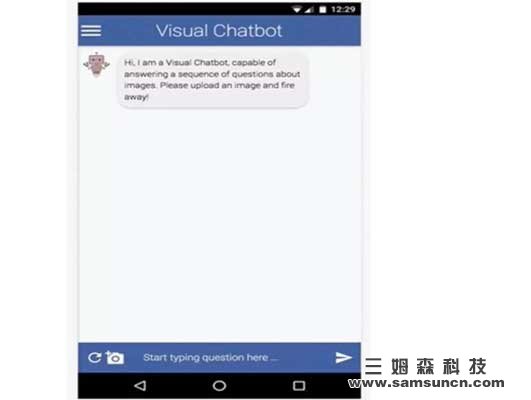
圖 | 視覺對話代理的演示。用戶會上傳一張圖片,代理則會以提出一個標題,“一個在中間有著鐘樓的大型建筑”來開始對話,再回答用戶所提的一系列問題。
由于視覺對話處于多個研究方向的交叉點上,它也促進了不同領域之間的合作來解決共有的問題。為了幫助這整個領域,Batra 和 Parikh 他們向對話研究者公開了這個視覺對話的數據集以及相關的源代碼,讓他們可以針對自己的問題開發自己的數據集。
對話研究一個可能會讓人感覺到反直覺的特性就是會把對話視為一個靜態監督學習問題,而非一個互動代理學習問題。在實質上,在監督學習中的每輪(t),對話模型都會被人工的“注入”兩個人類之間的對話,并被要求回答一個問題。但是機器的回答卻會被直接丟掉,因為在下一輪(t+1),機器會被提供正確參考標準,即含有人類的回答而不是機器的回答的對話。因此,機器永遠不可能引導對話,因為這樣會導致對話脫離數據集,讓它變得無法被評估。由于視覺對話處于多個研究方向的交叉點上,它也促進了不同領域之間的合作來解決共有的問題。為了幫助這整個領域,Batra 和 Parikh 他們向對話研究者公開了這個視覺對話的數據集以及相關的源代碼,讓他們可以針對自己的問題開發自己的數據集。
為了解決這一問題,佐治亞理工學院,卡耐基梅隆大學,以及 Facebook 人工智能研究院的研究人員們推出了全世界首個由目標驅動(深度加強學習),來幫助訓練視覺問答以及視覺對話代理的論文:“Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning”。
他們開發出一款合作“圖片猜測”游戲 GuessWhich,要求一個“提問者”Q-BOT 和一個“回答者”A-BOT 用自然語言進行對話。在游戲開始之前,A-BOT 會被提供一張 Q-BOT 不知道的圖片,而 A-BOT 和 Q-BOT 都會被提供同樣的對圖片的自然語言描述。在接下來的每輪中,Q-BOT 都會生成一個問題,A-BOT 對這個問題作出回答,然后兩者更新它們的狀態。在 10 輪之后,Q-BOT 必須猜測這張圖片,即在多張圖片中選出這張圖片。
我們發現,這些加強學習訓練出來的機器人的性能遠超傳統監督學習產生的機器人。最有意思的是,雖然監督學習的 Q-BOT 會嘗試模仿人類問問題,加強學習的 Q-BOT 卻會改變策略,提出 A-BOT 更擅長回答的問題,最終產生得到最多信息,最有益于團隊的對話。
由目標驅動的訓練的一個替代品就是使用可以區分人類和代替生成回答的對抗性損失或者知覺喪失。這個主意已經由 Facebook 人工智能研究院以及佐治亞理工學院的研究人員在研究了,并且會在 NIPS 2017(神經信息處理系統大會)公布他們的成果:“Best of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Mode”。
此外,這篇由德國的馬普信息學研究所,加州大學伯克利分校,以及 Facebook 人工智能研究院的研究人員所發表的論文:“Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training”也是針對這個話題的。這篇論文表示,在同一時間為一張圖片生成多個描述,要比一次生成一個更能讓模型學會如何生成更多樣化,更擬人的圖片描述。
我們需要開放的跨領域合作
作為人類,我們大腦功能種很重要的一部分都是通過視覺處理,而自然語言則是我們交流的方式。創造可以將視覺和語言連接在一起的人工智能代理是一個即興奮也困難的任務。我們在此文中討論了兩個研究方向:明確的視覺推理和擬人的視覺對話。雖然我們在進步,但是我們面前還有許多挑戰。為了保證向前的腳步不停,堅持在 Facebook 人工智能研究院,學術界,以及整個人工智能生態圈之間機型長期開放的基礎性跨領域研究合作是至關重要的。
